Scrapy Itemとは?
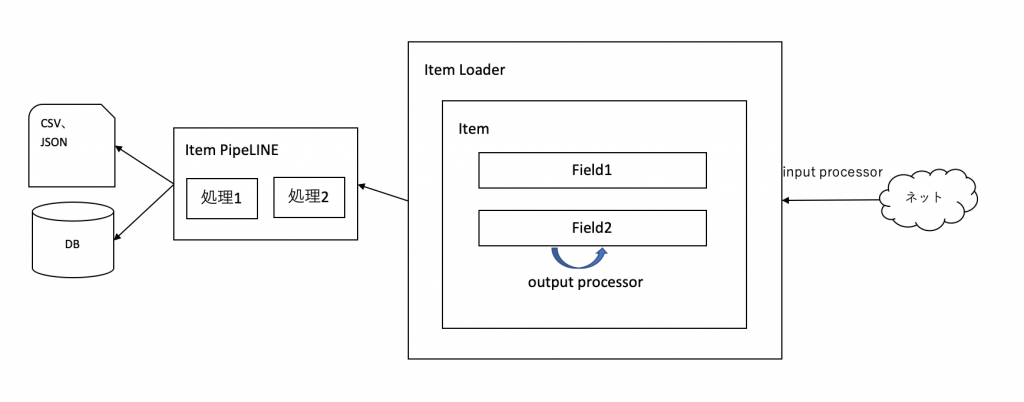
- Webサイトから取得したデータを格納する入れ物(オブジェクト)
- あらかじめ定義したフィールドに対してデータを定義する。
- データ構造を正確に保つことができる。(定義していないフィールドに値を入れようとするとエラーになる。)
- Item pipelineを使ってデータクレンジング、チェック、DB保存などを行うことができます。
- データの格納にはItem Loaderを用いて取得したデータの数値変換など便利機能を使えます。
Item Loaderのメリット
Spiderに直接取得データの変換処理を記述しても良いのですが、それだと複数Spiderを作る場合にコードの共有ができません。またspiderのコードの肥大化防止にも繋がるのでScrapyのコードの品質向上につながります。
Itemの定義
以下のファイルを編集します。
|
1 |
projects/プロジェクト名/プロジェクト名/items.py |
記述
以下のような感じで定義します。
|
1 2 3 4 5 6 |
import scrapy class BookItem(scrapy.Item): title = scrapy.Field() price = scrapy.Field() pass |
Itemを使う。
|
1 2 3 4 5 6 7 8 |
from プロジェクト名.items import BookItem class BooksSpider(CrawlSpider): def parse_item(self, response): loader = ItemLoader(Item=BookItem(), response = response) loader.add.xpath('title','titleを取得するXPath') loader.add.xpath('price','priceを取得するXPath') yield loader.load_item() |
loader = ItemLoader(Item=BookItem(), response = response)
Itemにデータを格納するのにItemLoaderを使います。
yield loader.load_item()
Webサイトから取得したデータをItemに格納する構文です。yieldで格納結果を出力しています。
実行
|
1 |
scrapy crawl spider名 -o ファイル名.json |
結果
以下のような出力結果が返ります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
[ { "title": [ " プロを目指す人のためのTypeScript入門―安全なコードの書き方から高度な型の使い方まで" ], "author": [ "鈴木 僚太【著】" ], "price": [ "¥3,278" ], "publisher": [ "技術評論社" ], "size": [ "サイズ B5判/ページ数 411p/高さ 24cm" ], "isbn": [ "商品コード 9784297127473" ] }, |
Item Loader
文字列から数値に変換などItemに格納する前後処理を記述するために使います。input processorやoutput processorの処理もitems.pyに記述します。
items.pyへの記述
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
from itemloaders.processors import TakeFirst,MapCompose,Join def strip_yen(element): if element: return element.replace('¥','') return element def convert_integer(element): if element: return int(element) return 0 class BookItem(scrapy.Item): title = scrapy.Field( input_processor = MapCompose(str.lstrip), output_processor = Join(' ') ) price = scrapy.Field( input_processor = MapCompose(strip_yen,convert_integer), output_processor = TakeFirst() ) pass |
input processor
XPathやCSSで取得したデータをItemに読み込みする前に何かしたい際に指定します。
- 先頭のスペース除去など
MapCompose(実行したい関数1、実行したい関数2)
何か入力値に対してItemに格納する前に関数を実行したい場合に使います。カンマ区切りで複数関数を指定できます。
output processor
アイテムの各フィールドに格納します。Itemでは結果はlistで格納されているのでlistからの取得方法を記述します。
- listの間に空白を加えながら結合して出力するなど
Join('間に入れる文字')
Listを結合して出力します。
TakeFirst
Listから最初の要素を取得します。
Item pipeline
Itemのデータクレンジング、チェック、DB保存などを行うことができます。
pipelineで使えるメソッド
| from_crawler(cls,crawler) | クラスメソッド。pipelineがインスタンス化される際に実行される。 |
| open_spider(self,spider) | spiderの開始時に実行 |
| process_item(self,item,spider) | 全てのitem pipelineに対して実行 |
| close_spider(self,spider) | spiderの終了時に実行 |
projects/プロジェクト/プロジェクト/pipelines.py
こちらのファイルにpipelineの処理は記述していきます。
以下は、itemに値が設定されているかチェックします。なかったらDropItemで例外出力します。
|
1 2 3 4 5 6 7 |
from scrapy.exceptions import DropItem class CheckItemPipeline: def process_item(self, item, spider): if not item.get('itemのフィールド名'): return DropItem('Missing フィールド名') return item |
設定ファイル(projects/プロジェクト/プロジェクト/settings.py)
|
1 2 3 4 5 |
# Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { "プロジェクト名.pipelines.CheckItemPipeline": 300, } |
用意したpipelineのclassを設定ファイルに登録します。数値が小さいほど先に実行されます。
こうすることで実行時(scrapy crawl スパイダー名)に自動的にチェックをしてくれるようになります。


この記事へのコメントはありません。