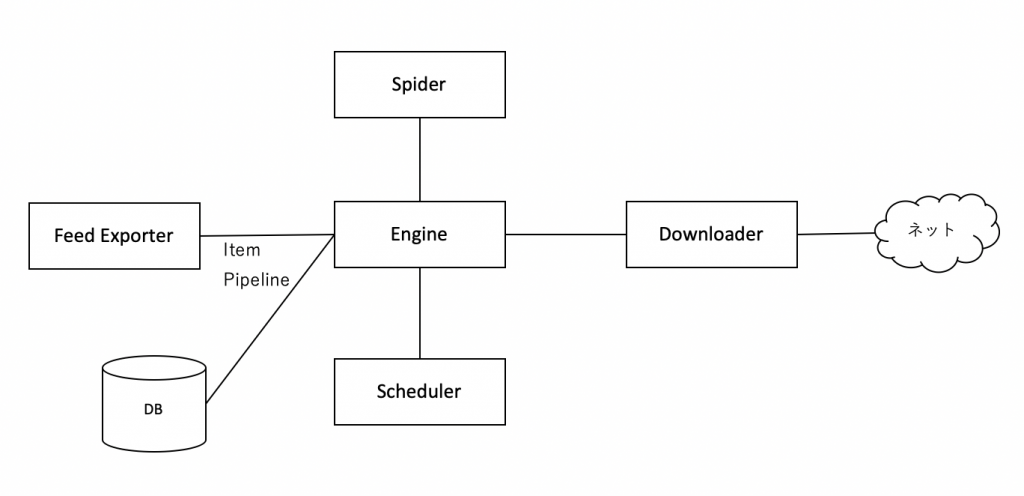
構成
Spider
Scrapyでは主にコードはこのクラスに記述をしていきます。ここに記述すればScrapyがうまいこと他の作業をやってくれるようになります。
開発者はSpiderで以下の物を指定します。
- 最初にアクセスするURLを指定
- リンクのたどり方を指定
- 必要なデータ抽出法を指定
Middleware
SpiderとEngineとの間の処理を拡張するために使います。
Item
Spiderでは取得したデータをこれに格納してEngineやItem pipelineを通じて送ることも可能です。
Engine
全ての構成要素を制御して一貫性を保つようにコーディネートしてくれます。
Scheduler
リクエスト処理をスケジュール管理します。具体的にはリクエストの順番をキューという形で保存します。
Downloader
リクエストで指定されたURLのWebページをダウンロードします。
Middleware
DownloaderとEngineとの間の処理を拡張するために使います。
Item Pipeline
抽出したデータ処理に関係します。具体的にはデータクレンジング(データ整形)、重複削除、データチェックなどをしてくれます。またデータベースへ保存したい場合などもこのItem Pipelineを使って行います。また、取得したデータ(Item)と取得順などが格納されています。
データベースへ保存したい場合は接続方法やSQLがデータベースによって異なるので必要に応じてItem Pipelineに処理を記述していく必要があります。
Feed Exporter
抽出したデータをCSVやJSONなどのファイルに出力します。関心事としてはあくまでファイル出力に関することだけで、データベースへの保存に関しては全く関与しません。
処理の流れ
上記はScrapyの構成をご紹介しましたが実際にどのような流れで処理が行われているかご紹介します。
- startURLに指定されたURLに対してspiderはEngineにリクエストを送ります。
- EngineはリクエストをSchedulerに転送します。
- Schedulerがリクエストをスケジュール登録し、スケジュール通りになったら再度Engineにリクエストが送られます。
- EngineはDownload Middlewareを用いてDownloaderにリクエストを送ります。
- DownloaderはインターネットからHTMLなどのWebページをダウンロードします。
- ダウンロードしたレスポンスはEngineに送付されます。
- EngineはSpider Middlewareを用いてSpiderにレスポンス結果を返します。
- SpiderではXPathなどを用いてレスポンスからデータを抽出するか、リンクなどを取得して再度リンクをリクエストしたりします。
- 最終的にSpiderはレスポンス結果をPythonの辞書に格納して、Feed Exporterなどでファイル出力します。
上記は、1リクエストを処理する流れになりますが、実際はScrapy上で多数のリクエストが同時に高速に捌かれてるようになっています。まずは1リクエストの流れを抑えましょう。


この記事へのコメントはありません。