スパイダーをVSCodeのステップ実行でデバッグする。
scrapy.cfgファイルがあるディレクトリに対して、ファイルを任意の名前をつけて保存します。(例:xxx_debug.pyなど)
|
1 2 3 4 5 |
from scrapy.crawler import CrawlerProcess from scrapy.utils.project import get_project_settings from projectディレクトリ名.spiders.spiderファイル名 import XXXSpider process = CrawlerProcess(settings=get_project_settings()) process.crawl(XXXSpider) |
from scrapy.utils.project import get_project_settings
projectフォルダ配下のsettings.pyを読み込むために利用します。
実行方法
VSCode上でSpider内の任意の行に赤ポチをつけます。
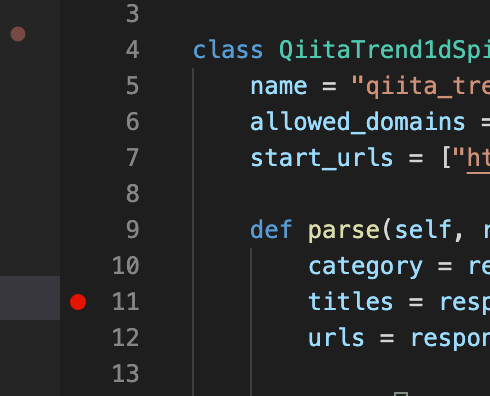
これで上記用意したコード(xxx_debug.py)内でRun→Start Debuggingをクリックすればそこでブレークポイントが止まってデバッグすることが可能です。
Python loggingでデバッグする。
設定
|
1 2 |
LOG_FILE = 'log.txt' LOG_LEVEL = 'DEBUG' |
LOG_FILE
出力するログファイル名を指定します。
LOG_LEVEL
ログレベルを指定します。指定したログレベル以上のレベルのログを出力してくれます。本番を想定するならINFOと設定しておくのが良いでしょう。
ちなみに、上記のDEBUGはデフォルトのログレベルになるので記述しなくても問題はないです。
サンプル
|
1 2 3 4 5 |
def parse(self, response): logging.debug({ 'status': response.status, 'url': response.url, }) |
出力結果
スパイダーを実行したら以下のようなログが出力されます。
|
1 |
2023-06-08 22:13:29 [root] DEBUG: {'status': 200, 'url': 'https://qiita.com'} |
parseコマンドを使う
parseコマンドを使えばメソッドや階層などまで出力できます。ユースケースとしては「想定した宛先(URL)に送られてきて、想定した結果が返ってくるかを一覧でまとめて取得できます。)
以下のように指定します。
|
1 |
scrapy parse --spider=spider名 -c 実行したいparseメソッド名 -d 調べたい深さレベル URL |
具体例
|
1 |
scrapy parse --spider=kinokuniya_spider -c parse https://kinokuniya.com |
出力結果
|
1 2 3 4 5 6 7 8 |
>>> STATUS DEPTH LEVEL 1 <<< # Scraped Items ------------------------------------------------------------ [{'category': 'トレンド', 'titles': ['Vue3の衰退を招いたのは<script setup>とCompositionAPIかもしれない という考察', '【JavaScript】DataTablesが超便利すぎる', 'Pythonでボリンジャーバンド、売買シグナル、バックテスト']}] # Requests ----------------------------------------------------------------- [] |
STATUS DEPTH LEVEL 1
階層の深さレベル1を指しています。リンクを辿るほど深さが増してレベルも増えます。
ページネーションのあるページをクロールする例で言えば、1ページ目がレベル1、2ページ目がレベル2、3ページ目がレベル3という形になります。
Scraped Items
スクレイピングで取得した項目を指しています。
Requests
リクエストしたurlが表示されます。次のリンクがない場合は空配列が表示されます。
scrapy shellを使う
scrapy shellはターミナルなどで以下のコマンドを実行する機能もありますが、spiderから直接呼び出すことも可能です。
|
1 2 3 4 5 6 7 8 9 |
from scrapy.shell import inspect_response class QiitaTrend1dSpider(scrapy.Spider): name = "xxx" allowed_domains = ["xxx.com"] start_urls = ["https://xxx.com"] def parse(self, response): inspect_response(response,self) |
それでspiderを実行すると、inspect_responseを仕込んだ箇所でターミナルが止まりそこからシェルが起動してデバッグできるようになります。(Railsをやったことがある方であればイメージ的にbyebugに近いです。)
止めた状態で変数を自由にデバッグしたりすることができるのでxpathの動作確認などがスムーズに行えたりします。


この記事へのコメントはありません。